那些养猫的人,进家门第一件事就是喵喵喵喵地叫,希望看那个小东西从哪个角落里钻出来欢迎你,直到某一天小猫跑掉了,喵喵了很久也不见它过来在你脚边蹭蹭,才忽然惊觉房子那么大那么空。
设计初衷
灵感来自于某个小哥在群里闲聊的时候,谈及自己一起提交过一个知名网站分站的源码泄露,并且收益不菲,我当时一愣,没想到源码泄露这个漏洞还能赚不少积分,于是研究一番后,决定写一个专门扫描网站重点敏感信息泄漏的软件,这个软件的功能包括这三点。
- 扫描备份文件
- 扫描SVN/GIT源码泄漏
- 扫描WEBINFO页面信息泄漏
虽然只是三点简单的功能,但是拆开后来说,涉及到的知识点有点杂。所以写此文章,作为笔记,希望各位朋友指点一二。
工程设计
备份文件扫描
先分析功能的第一点,扫描备份文件。首先想到的是搜集一些备份文件的字典,然后拼接,最后访问验证。但是根据我的经验,有很多很多网站的备份文件命名方式都是以该网站的域名作为文件名。举个例子,wwwlangzi.fun这个网站,根目录下有个备份文件,备份文件的名称是langzi.rar,这样的话字典没办法扫描到,所以需要在程序中实现,比如先切割域名,然后加上.bak,.rar,.zip,.tar.gz等等组合成新的备份文件路径,举个现实中的例子。
这样会大大的增加扫描成功率,并且备份文件的字典都是我精心挑选出来的,扫描率也是非常高的,举个例子。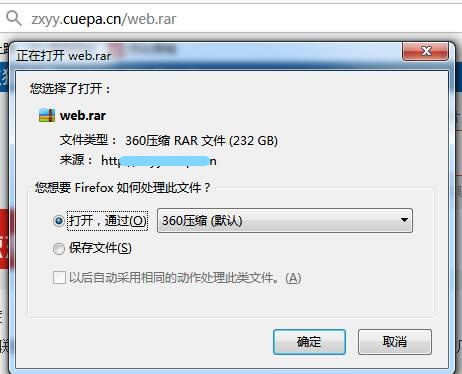
源码泄露与敏感信息泄漏
关于SVN,GIT源码泄漏的危害都是比较大的,提交上去平台不会不管,所以还是有扫描的价值,至于webinfo我个人觉得无关紧要,不过为了不错过,于是顺手加上去了。
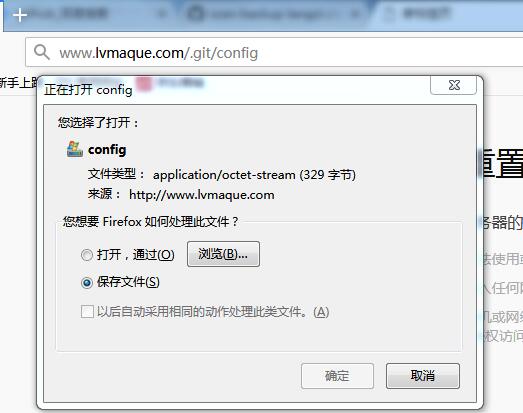
漏洞验证的方式其实很简单,SVN泄漏的判断方式是在网址后面加上/.svn/entries同理GIT源码泄露是/.git/config,webinfo是/WEB-INF/web.xml。如果页面存在并且状态码返回200,就进行下一步匹配页面关键词。存在SVN泄漏的页面会出现’dir’和’svn’两个词,GIT泄漏返回的页面存在关键词’repositoryformatversion’,至于webinfo关键词是’<web-app’,有了这些验证思路,想必大家都能够想到接下来该怎么办了。
提高速度之进程池技术
为什么不用多线程呢?答案是慢,由于GIL的存在,每次只能存在一个线程,多线程的原理是某个线程在等待的时候,另一个线程启动。对于哪些存在网络等待或者延迟等待的软件来说使用多线程可以,但是这个扫描器追求的是最高的速度。在发送大量的网络请求前提下,使用进程池往往速度优于多线程。
提高速度之请求方式
一个两个网站请求或许会很快,但是如果大量的网址请求的时候可能就会网络堵塞了,因为要扫描备份文件,总所周知备份文件基本上都大于1M,所以我们可以使用head头部请求方式来验证备份文件是否存在并且判断备份文件的大小。head请求方式速度远远快于get请求方式,并且还可以根据返回的头部信息判断大小。
返回的头部信息里Content-Length对应的是网址的内容大小,所以基于这一点扫描备份文件的速度就大大提高了。至于切割域名作为字典名很好理解,只要在网址上 + ‘/‘ + urlx.split(“.”,2)[1]然后再去拼接常见后缀即可。
交互模式
作为一个主动化的扫描工具,需要主动采集几百几千几万个网站,保存在当前目录下的url.txt文本当中,然后启动程序,设置进程数量。程序开始启动扫描,成功的结果自动保存在当前目录。
实例演示
首先用采集器随机采集一批网站,然后开始扫描。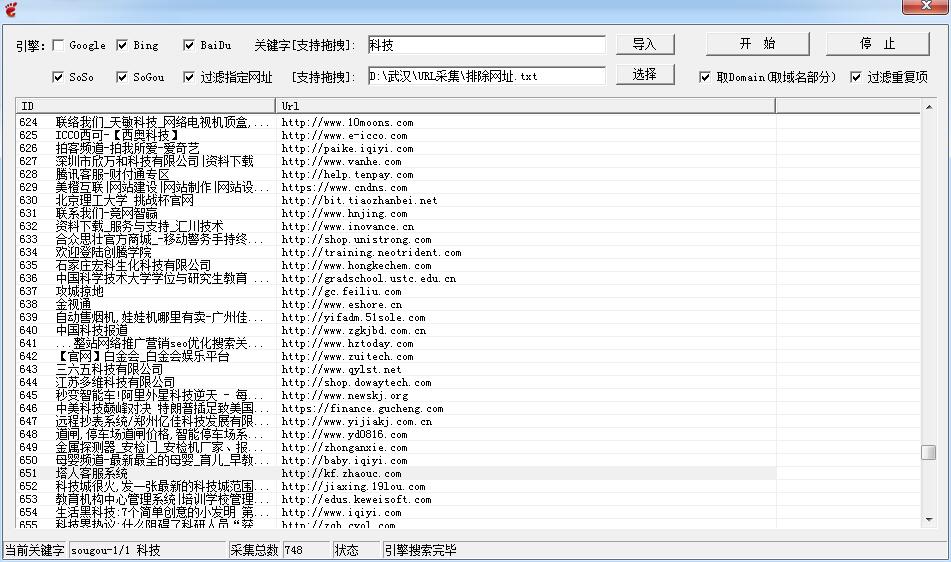
很快就扫描到了好几个备份文件和信息泄露。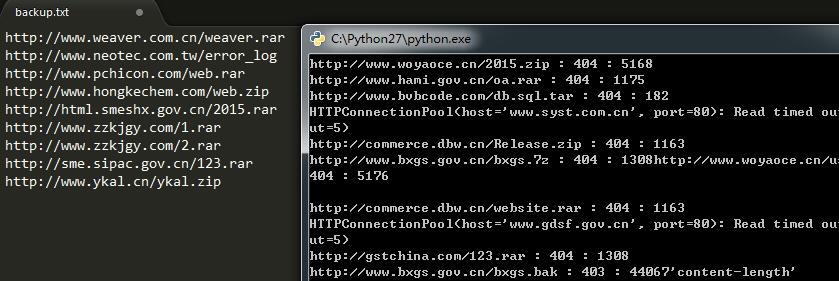
结语
这个扫描器优点投机取巧的意思,在大量的网址前提下,快速扫描和识别是否存在敏感信息泄漏。技术含量不高,但是扫描到的结果怎么利用就大有讲究了。你可以下载这些备份文件,网站源码,然后做代码审计,分析。进一步发掘更大的漏洞等等….
打包好的下载地址
禁止下载
Lang_BackUp_备份文件扫描_1.0
使用动态规则+精准字典+多进程进行扫描验证
使用方法相同。
Lang_BackUp_备份文件扫描_2.1
扫描备份文件的代码其实直接从Yolanda_Scan0.99测试版拖拽下来,虽然说是三个月前写的扫描器,但是扫描备份文件的功能还是挺齐全的,除了固定的字典外,每个URL还包含了100多种根据url生成规则的新备份文件路径。
使用方法还是和之前的一样,采集url放在同目录下的url.txt里面,右键启动扫描器即可。
因为扫描的字典规则变多了,扫描的过程会慢一些。
但是扫描得更加彻底,号称连你的内裤都能扫出来
相对来说2.1比1.0扫描更全面,但是耗时更久
Lang_BackUp_备份文件扫描_2.3
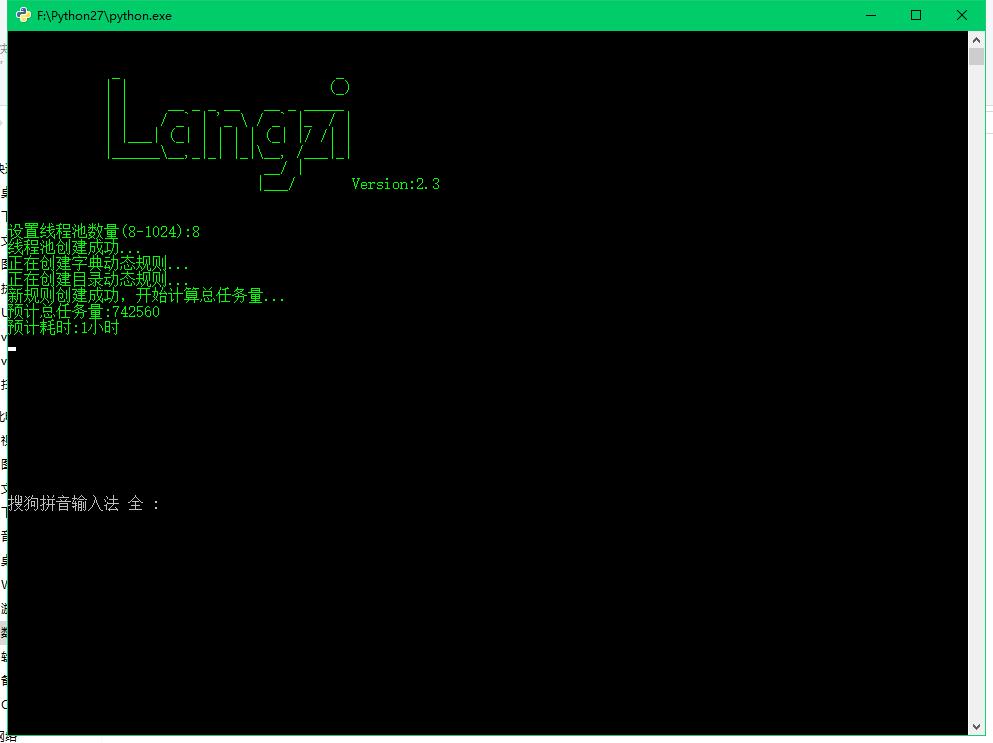
2.3版本是扫描最最最最最彻底时间最最最最最最长的一个版本
Lang_BackUp_备份文件扫描_2.3.exe
自动化扫描指定网站的备份敏感文件
【运行要求】
1 电脑要插网线
2 CPU:1核或以上 [可能会卡死机]
3 内存:256M或以上 [可能会卡死机]
4 宽带:1M或以上 [可能会卡死机]
5 最低线程数: 2或以上,不开的话默认是CPU核数 [可能会卡死机]
【使用方法】
采集网址放在url.txt里[支持带http和不带http]
【更新说明】
1 新增备份文件规则
2 根据域名生成特定的备份文件字典,每个网址生成的专属规则多达1000+
3 新增原谅的配色
4 提供一个更加全面的字典,可以把目录下的all_dict.txt里面的内容复制到rar.txt中(不推荐)
5 扫描更加彻底,但是需要消耗的时间更多更多更多更多更多更多更多更多更多更多更多,建议扫描期间去做一次大保健再回来
6 修复无法导入自定义字典
7 新增数千个妹子
2018年8月11日 20:12:46
【重点说明】:
2.3版本扫描时间周期长到你昨晚大保健回来睡一觉应该才扫描完毕
总而言之,如果只是想快速的扫描一下常见备份泄露用1.0版本
想稍微深度扫描一下备份顺便做下大保健就是用2.1版本
没有2.2版本,2.2看上去比较2
如果你有大把的时间可以浪费的话,建议使用2.3版本
报道页面的样式有点丑,不过影响不大
各版本总结
相对来说呢,1.0版本最好使,速度快字典精准度高。
2.1版本扫描更加彻底。
2.3版本扫描更加更加彻底,但是耗时更长。
所以综合来说还是1.0版本最友好,推荐使用1.0版本
不出意外的话,扫描备份这一块以后不更新了,以后把备份文件和敏感信息泄露总结在一起,传送门

